
Blog
May 5, 2022
Data Quality Series Part 4: An Introduction to Data Reliability Engineering






In part one of this series, we presented the four main causes of bad data quality: issues keeping up with data scale, errors propagating in dynamic ways, abnormalities that aren't necessarily bad data, and differing uses of data across departments.
In part two we identified that the usual suspect (organizational scale and complexity) is actually a cover-up for the real root cause: bad data governance.
In part three we introduced three characteristics that help organizations implement effective data quality: integration into data product development, automation to detect exceptions, and transparency to build trust.
In this post we continue the series by providing practical tips on implementing the enabling technology (in early 2022) to support an integrated, automated, transparent data reliability engineering function within an organization.
An Introduction to Data Reliability Engineering
Companies seeking a competitive advantage based on their data insights must build a platform (aka “defining a data stack”) that ensures trust in the data at scale. A couple years ago, we predicted that the governing of data would become an engineering discipline over time. Today, that prediction is coming true in what is becoming known as Data Reliability Engineering (DRE). This practice embraces the core tenents of Site Reliability Engineering (SRE) and applies the philosophy to data teams and their products.
Getting Comfortable With Embracing Risk
One core tenet of SRE, embracing risk, fits perfectly into the reality of organizational data systems: there will never be a shortage of exceptions wreaking havoc within the data. So, the focus should shift from preventing errors at all costs to embracing and handling them gracefully, predictably, and transparently. It’s an interesting topic as explored earlier this year by Great Expectations core contributor Abe Gong in his talk on Embracing Risk in DataOps.
Just as Site Reliability Engineering is a set of practices that matured from the DevOps movement, Data Reliability Engineering is evolving from DataOps practices. In both cases, the practices are supported by enabling technology platforms to consistently deliver a product (a website, application, data feed, dashboard, etc.) to different groups of end-users at a predictable level of service. Furthermore, the overarching goal is to accept, account for, and accommodate risks associated with an application (i.e., codebase) and associated infrastructure.
Extending Reliability to Data Products
In the case of Data Reliability Engineering, however, there is additional complexity associated with applying the same principles and quality standards to data products. How to ensure raw data is validated and aggregations accurate? Operationally, how to ensure processes run on schedule and complete within the expected time? Risk must be accounted for at each data level, from atomic to aggregate, and end users must be able to confidently use and consume data products in the very likely event of an exception.
Ultimately, data consumers are trying to answer the question “should I use this data” during the data discovery process, and they need to know more than the column and table descriptions to make that decision. Specifically, they need enough information to build trust that using a particular dataset will help them achieve their goals with minimal risk. To help with this, DRE systems not only support the reliable transmission of organizational data, but also treat the metadata that describes the quality of your data as a first-class data type, enabling it to flow across the organization. Just like other first-class data types, this metadata must be converted into a data product to realize value, which is why effective DRE systems focus on providing it to data consumers in a usable form at the right time.
Managing Expectations and Helping Your Data Engineers
DRE Systems also help codify data consumer expectations and dictate team response to meet these expectations. Specifically, they measure Service Level Indicators on your data to define what is necessary, enable the specification of Service Level Agreements so data consumers know what they can expect, and define separate Service Level Objectives to drive team response over time.
The standards and integrations required for successful DRE systems have the effect of “spreading risk” (of failure) from individuals on the data team to the data team as a whole. The weight of failure no longer falls on the shoulders of one technical resource. With acceptable standards and exception handling defined as code and integrated into the data infrastructure stack, any member of the team can step in to provide troubleshooting and resolution. This lends itself toward eliminating data silos, which are commonly arising within many organizations’ strategic data projects today.
Testing, Cleansing, and Monitoring
To ensure that data is usable and arrives on time, several processes need to be implemented and executed harmoniously. The most common of these processes are tests that are built to run during the development of data pipelines. Additional tools to promote data upkeep are cleansing, to automatically correct common data errors, and monitoring, to identify errors as they arise.
Testing
Most will be familiar with the use of unit tests to control edge cases, but the limited scope of unit tests can fail to catch inconsistencies in the broader system when all the pieces of a pipeline are put together. Additionally, unit tests rely on the developer to identify edge cases.
Integration tests are the next obvious step for testing as they can cover a data pipeline from start to end and can highlight problems as different components are combined. However, both are limited in their nature as they require development to be implemented and maintained.
A step above is fuzz testing. A fuzzer is a program that takes semi-random data and automatically injects it into your data pipeline to detect bugs. By removing the need for a developer to define and develop test cases, the main advantage of this method of testing is that it removes any bias or preconceptions about the data pipeline itself. By eliminating human bias, a tester may be able to locate errors or bugs in the pipeline that were overlooked in unit or integration tests.
Cleansing
While testing is great for identifying problems in the system, manual corrections to common data validation errors are time intensive and prone to propagating additional errors. Data cleansing is a solution to this problem that enables a pipeline to automatically correct common errors in data (data type, extra characters, differing formats, etc.). This has two advantages: it allows the system to continue processing data without developer intervention, and it reduces the number of errors reported—allowing logs to highlight more unique problems.
Monitoring
While testing and cleansing will catch a significant number of errors, there are always additional data issues that sneak through. The easiest way to manage these is to set up monitoring functionality within data pipelines to detect any failures within the systems. Running expectations from data tests while running on real data is a great way to test out a monitoring system. Additionally, running anomaly detection within a data pipeline can catch additional unplanned errors.
Harvesting Metadata
Tracking what has been done to ensure data quality is nearly as important to building trust in the data as the data quality measures themselves. By demonstrating to data consumers which data has been rigorously verified, you reduce the need for (and likelihood of) duplicate validation work while also avoiding data misuse.
Issue Taxonomy
To start, you should put in place (and train your data teams on) a taxonomy of issue types, then use this consistently across your testing, cleansing, and monitoring tools. While this can feel formal and dry, it provides the standards to build consistency in naming, making the metadata much easier for data consumers to understand. Below is a table that provides potential metadata to capture on data quality tests.
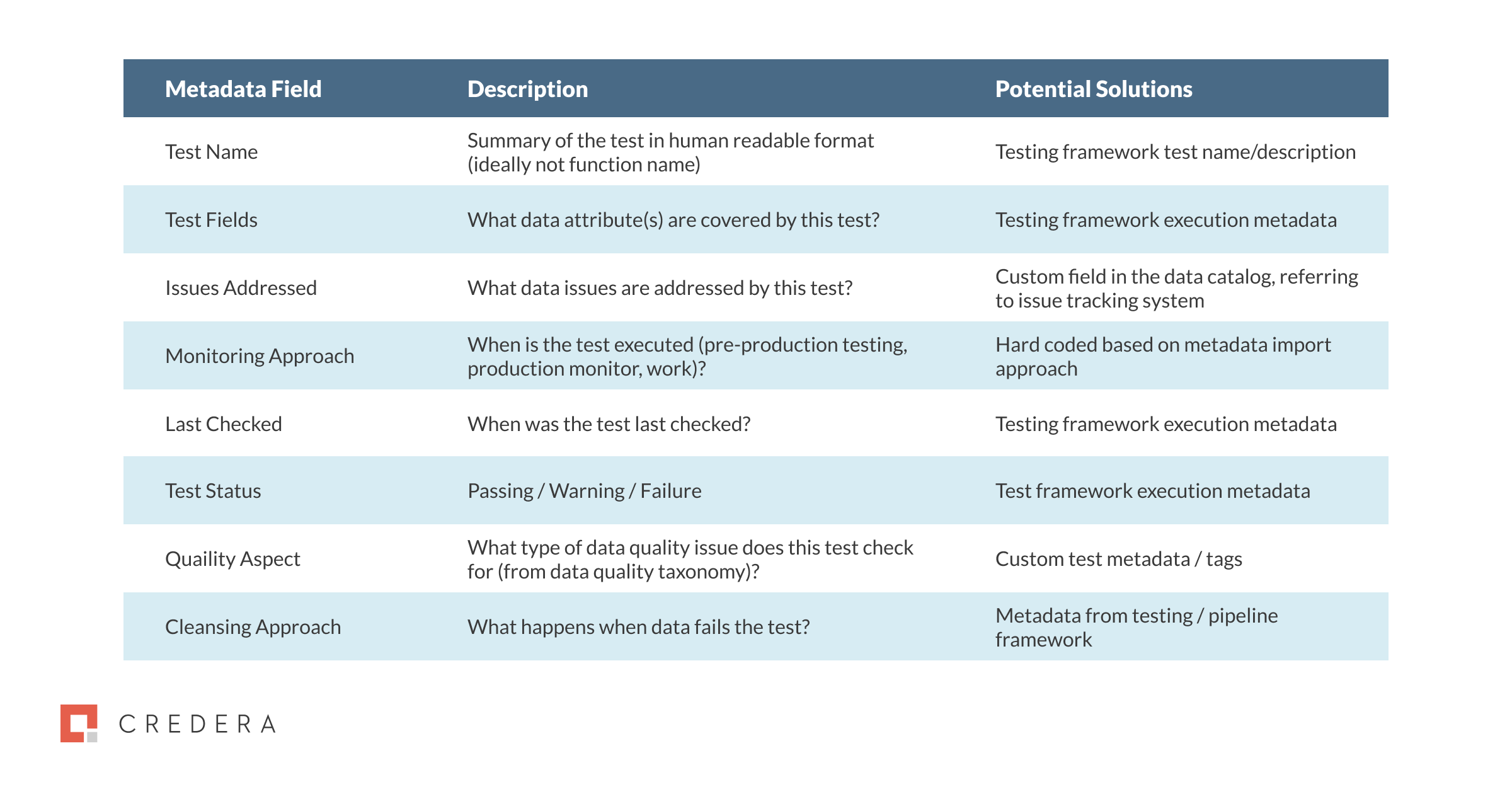
Table 1: Examples of Data Quality Tests Metadata Capture

Scoring Quality Levels
A data-issue taxonomy also helps to demonstrate the coverage of testing in place against the types of problems that could occur. Many system providers and thought leaders suggest building an overall quality score for each dataset. The key advantage to this score is that it is easy to include in the search results listings (rather than data product detail page) of your data catalog and/or data marketplace. It provides an “at a glance” summary of your data quality.
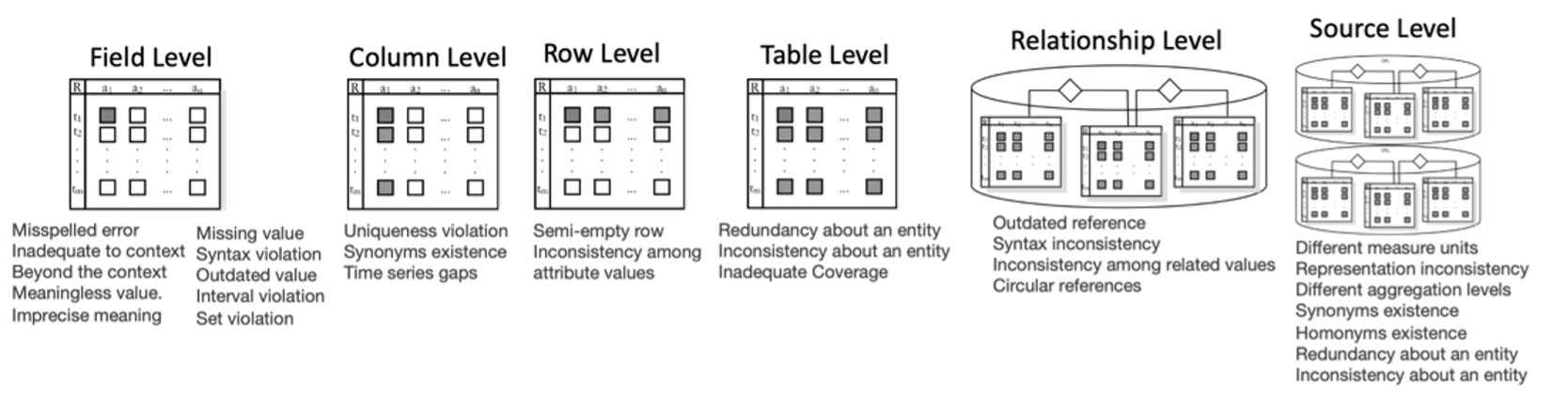
Figure 1: Data Taxonomy - Sourced from A Formal Definition of Data Quality Problems
To score in a way that is useful and not misleading, you must demonstrate coverage of all the potential problems that could occur. However, data-issue coverage is not nearly as simple as code coverage, because both the data processing code and the data itself will change over time. Demonstrating which types of issues (from the taxonomy) have been validated is essential. With a taxonomy in place, you can instrument your continuous integration processes with checks for data tests, test compliance, test coverage metric calculations, and test metadata extraction. Only after these practices mature across your organization, can you safely move on to generate and share a summary data quality score that is derived from these metrics. The key advantage to this score is that it is easy to include in the search results listings (rather than data product detail page) of your data catalog and/or data marketplace. This is something we will expand upon later and discuss how similar concepts can help reinforce trust in the data products used by stakeholders.
As discussed above, by adopting standards and implementing processes for the cleansing, testing, and monitoring you can often avoid many common data issues. Unfortunately, the systems that we put in place are never perfect and will inevitably encounter errors and problems will arise.
Up Next In the Series
In our coming articles, we will discuss methods for how you can increase the efficacy of your data pipelines and support them with a structured process for addressing unpleasant bugs when they arise.
If you’d like to have a conversation about these methods for controlling your data quality with one of our data experts, reach out at marketing@credera.com.


Video
Aug 24, 2021
The Credera Brief | Leveraging Data for Successful Marketing
The Credera Brief video series distills trends and ideas from Credera leaders and experts. In this video, Vincent Yates,...
Whitepaper
Oct 12, 2021
Redefining Data Governance: How to Let Data Govern Your Organization
Today’s organizations are failing to find success with top-down, traditional data governance. The following whitepaper outlines a strategic approach for success in redefining...
GET THE WhitepaperBlog
Feb 19, 2021
Realizing Value From Your Data Lake: Lessons Learned and Four Critical Mistakes to...
Data lakes are a great way to organize your company’s data, but a staggering number of data lakes fail to reach their true...


Contact Us
Let's talk!
We're ready to help turn your biggest challenges into your biggest advantages.
Searching for a new career?
View job openings