
Blog
Apr 5, 2023
Supply chain: Artificial intelligence, mathematical optimization & reinforcement learning






Over the past few years, events such as the COVID-19 pandemic and the war in Ukraine have caused significant disruptions to supply chain operations. These disruptions are made even more complex because many supply chains are global in nature and operate across multiple markets, cultures, and time zones.
Historically, supply chain management has typically involved a reactive approach to disruptions, leading to issues like material shortages and delays that contribute to inflation. To overcome such reactive approaches and other issues, like demand forecasting and inventory management, supply chains need a more dynamic and proactive approach. Artificial intelligence (AI) and mathematical optimization are currently employed to mitigate some of these challenges. However, they have their limitations.
Advancements in reinforcement learning (RL) have the potential to offer a significant edge over conventional AI and optimization methods. This article will explore the different strategies for addressing supply chain issues and emphasize the advantages of reinforcement learning when integrated with other methods.
Mathematical optimization
The approach of mathematical optimization involves the configuration of facilities, warehouses, resource allocation, and other elements under operational constraints. Businesses frequently assess their supply chains to ensure maximum efficiency to maintain a competitive edge. Through network optimization, companies can evaluate how their supply chain systems would perform in various scenarios and define strategies to handle these cases with their suppliers, leading to the implementation of cost-effective and low-risk supply chain plans.
Supply pla
nning entails managing the inventory produced by the manufacturing process to meet the demand specified in the demand plan. The objective is to strike a balance between supply and demand to provide the best service level at the lowest cost.
Mathematical optimization illustration
To illustrate, let’s examine the supply chain issue of producing and delivering masks for COVID-19. Imagine a company has three production plants, two distribution centers, and needs to deliver the masks to 100 stores. Our goal is to determine the most cost-effective delivery route from the production plants to the sales stores where end users purchase the masks. We mathematically formulate the problem by defining variables for the quantity and sales of inbound and outbound transportation.
source_to_distribution = quantity of inbound shipment from plant to distribution
distribution_to_sales = quantity of outbound shipment from distribution to sales
cost_source_to_distribution = quantity inbound shipment from plant to distribution
cost_distribution_to_sales = quantity outbound shipment from distribution to sales
Using the variables, we can define our objective function as:
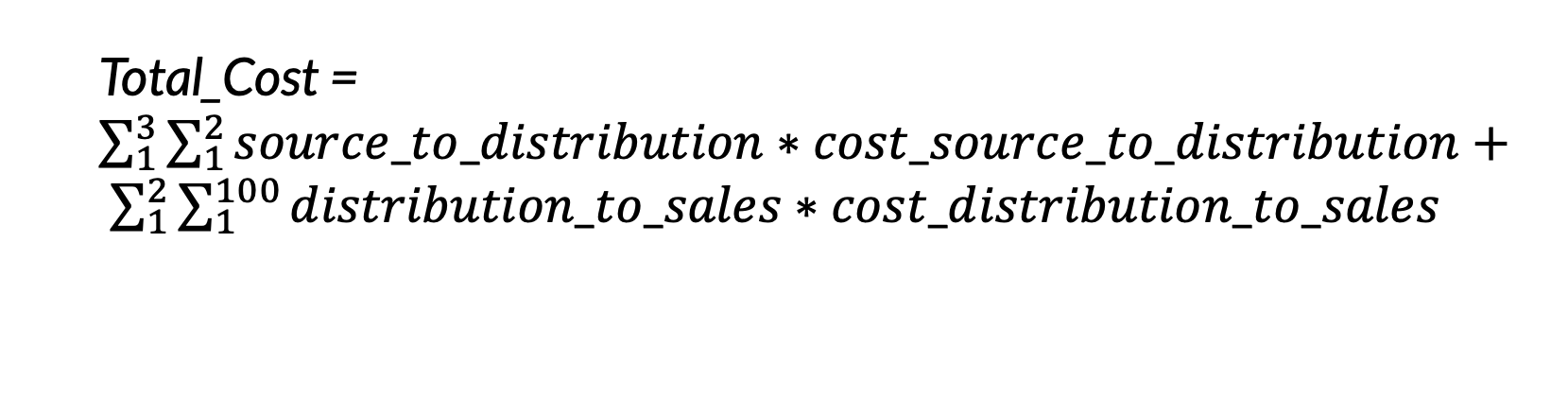

The objective function can be solved using Integer Linear Programming, which maximizes or minimizes a linear function subject to constraints represented by linear equations or inequalities.
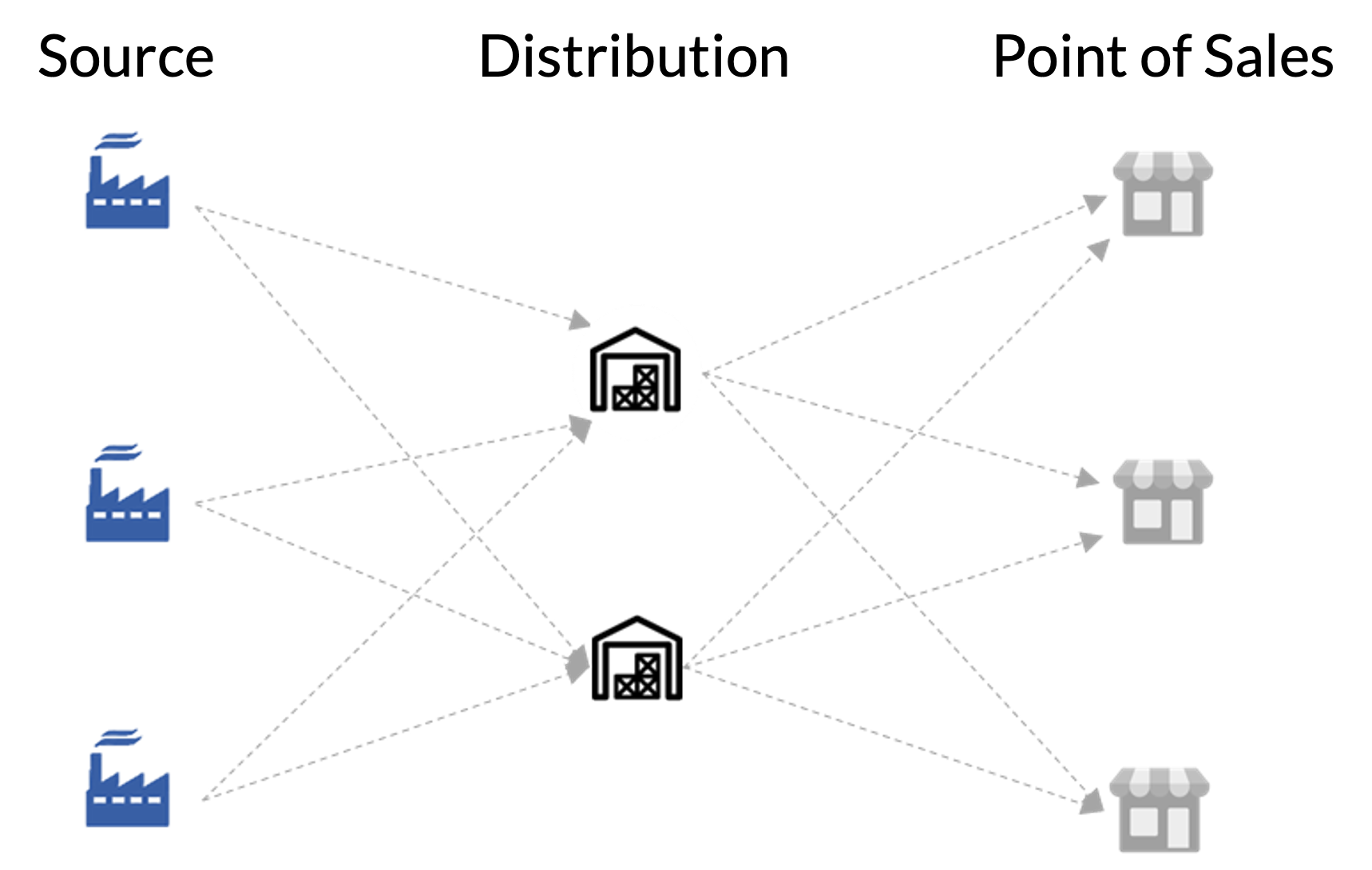
Mathematical optimization limitations
Although these traditional optimization techniques offer effective solutions for supply chain optimization, their main limitation is their inability to adapt to market changes. If the market undergoes significant shifts, the constraints and objective function must be reevaluated, and the optimization problem must be re-solved from the beginning. This may take more time than a business can afford when responding to market changes.
Artificial intelligence
Artificial intelligence is a broad term that describes all methods by which a computer system learns from data to enable better decision making. In the context of supply chains, a recent study found that supply chain management that incorporates AI led to significant improvements in logistics costs, inventory levels, and service levels, with 15%, 35%, and 65% reductions, respectively.
A few areas where AI is especially beneficial in supply chain are demand forecasting, quality assurance, and anomaly detection. Accurate forecasting is crucial for assessing current capacity and allocating resources in preparation for future demand, while keeping production and warehousing costs low. Effective quality control processes reduce the high costs and risks associated with defective products making it out to customers. Accurate and real time anomaly detection in operational supply chain data enables catching potential cascading disruptions early on.
Artificial intelligence illustration
Continuing the example of the COVID-19 mask supply chain problem, demand forecasting models might consider factors such as population density, rate of infection, age distribution, and mask mandate laws when predicting demand for different areas. To optimally distribute the masks, predicted demand would have to be weighed against other variables such as current inventory levels and rate of production.
Along with demand forecasting, computer vision (CV) could be used to detect mask defects. CV models trained via deep learning have shown to be as good or better than humans at certain tasks; they reduce labor costs with greater efficiency and less variability. For anomaly detection, unsupervised approaches could be used to detect patterns in operational data that do not fit the norm. Maybe an area that was expected to have enough masks for predicted demand suddenly encounters a spike in mask purchases. The ability to detect situations like this early is crucial for healthy supply chain operation.
Artificial intelligence limitations
While the traditional AI approaches discussed provide measurable supply chain performance increases, they are limited in their scope. Even if demand could be perfectly predicted by advanced AI models, numerous factors and constraints within and external to the supply chain have to be considered. While some of these could be solved by other AI systems, each of these systems are still only geared towards a specific problem within the supply chain. There is a need for a global optimization approach that considers the entire chain.
Reinforcement learning
Reinforcement learning is a promising approach to tackling complex supply chain problems. It leverages both artificial intelligence and optimization to create a computer program, known as an agent, that aims to maximize a user-defined reward function to achieve a goal. The agent operates in an environment where it can take various actions to achieve different states. For example, an agent can increase supply when faced with an understocked inventory. By taking such actions, the agent learns a policy, which is a series of actions the agent can take in an environment, and the goal in RL is to learn an optimal policy to maximize expected reward based on the positive and negative feedback the agent has received from previous actions.
This exploration of actions and states is called learning, and there are two forms: offline and online. In offline learning, the agent considers all the data at once, learns an optimal policy, and then uses this policy thereafter. In contrast, with online learning the agent considers a single data point at a time to learn an optimal policy and keeps learning as new data comes in. With the ability to perform online learning, reinforcement learning agents can quickly adapt to evolving scenarios and learn optimal decisions on the fly, making them uniquely suitable for supply chain problems. They offer the best of both worlds with holistic supply flow optimization and adaptive decision-making.
Let’s revisit the supply chain problem for COVID-19 masks. There are two interconnected issues at its core: demand forecasting and inventory management. While AI and optimization can independently solve aspects of these two issues, RL offers a solution that addresses both and also accounts for their dependency.
Reinforcement learning illustration
To address the COVID-19 mask supply chain problem, we can use an off-policy online Q-learning algorithm to enable the agent to learn and adapt to different policies, providing greater flexibility to deal with the volatility of supply chains. We define the state-space with three possible states: understocked, overstocked, and correctly stocked (defined as having 10% more inventory than expected sales). The agent can take three actions to transition from one state to another: increase, decrease, or maintain production levels. The agent is rewarded for its actions and the state it reaches, with a reward of 10 for correctly maintaining inventory, -1 for maintaining an overstocked inventory, and -100 for maintaining an understocked inventory. Note that these environment definitions are simplified for clarity and that a more complex setup would typically be used.
With the action space, state space, and reward function established, the scenario can be formally written as a reinforcement learning problem:
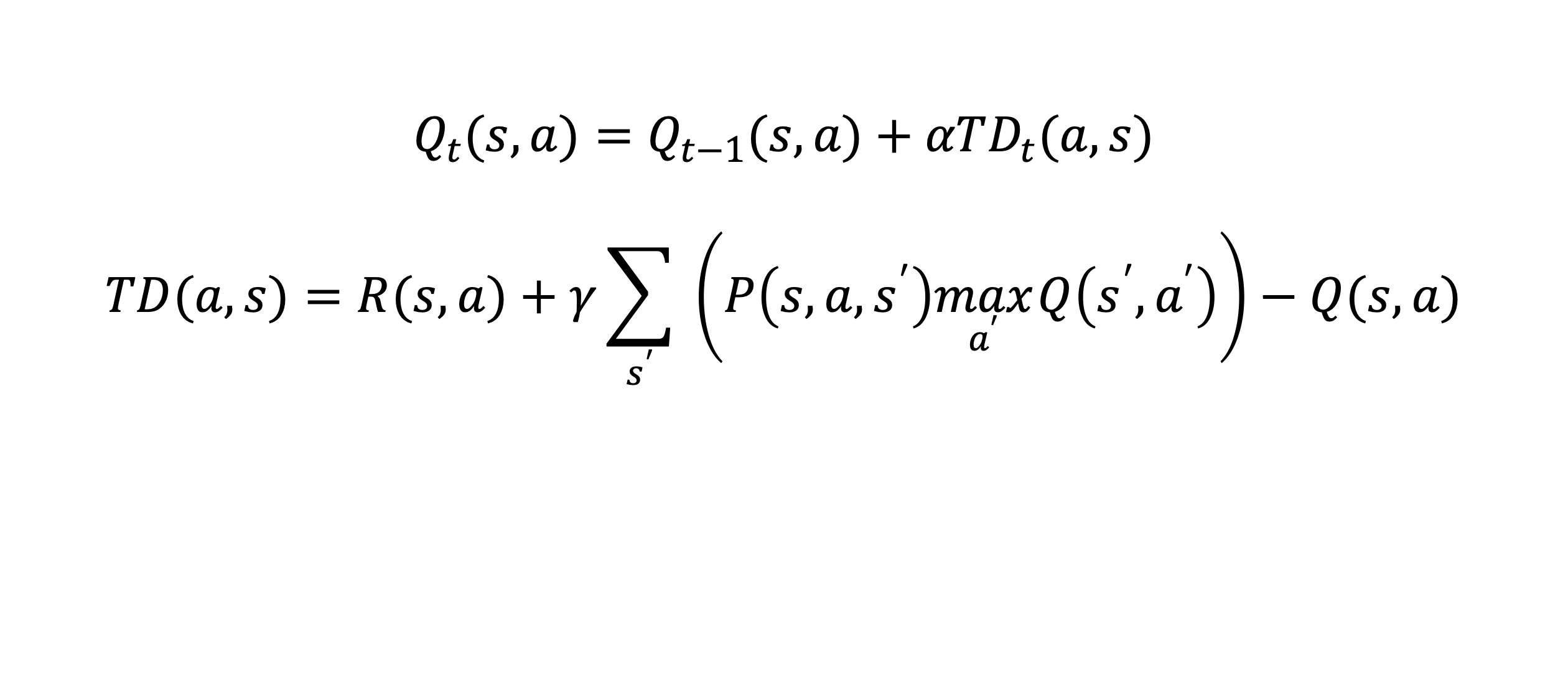
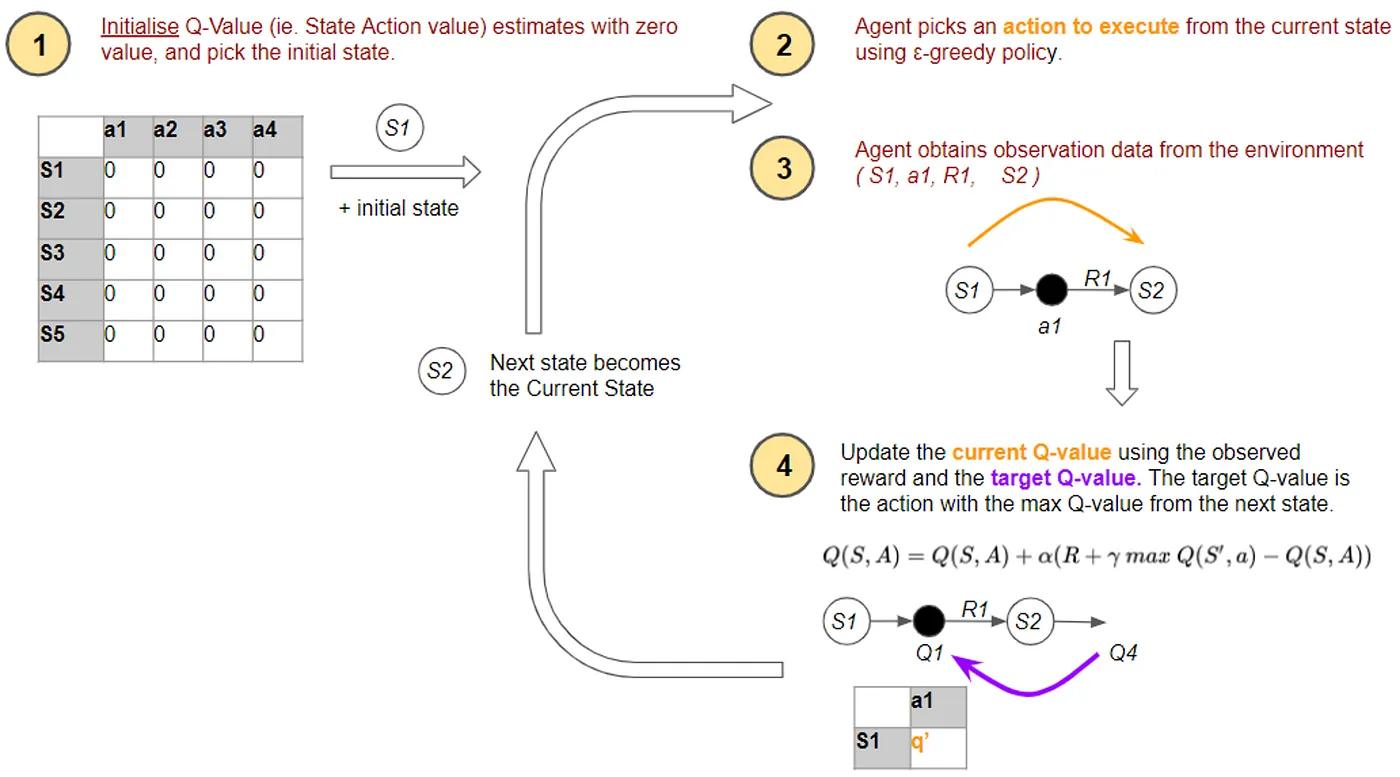
Qt(s,a)is known as the Q-value the agent learns for the current time step. The Q-value is simply a score that represents the currently known value of taking action a in state s and is calculated recursively from Qt-1(s,a), which is the Q value from the previous time step. α is a learning rate we can tune which weighs the importance of TDt(a,s), the temporal difference between Q-values of the current state and future possible states. Simply, temporal difference can be thought of as the estimated reward when moving from the current state to a future state. It is calculated by taking the reward R(s,a) the agent receives when taking action a from state s, adding an estimate of optimal future value over all possible states weighted by y, and then subtracting the current value. When y is near zero, the agent prioritizes immediate reward, but when y is near one, prioritizes long-term reward. So, the agent explores its environment, continually re-estimates future rewards at each time step via temporal difference and updates its policy to maximize expected future reward. This Q-value update is visualized in Figure 2 for an abstract state space S and an abstract action space A.
Using this problem formulation, an RL agent can leverage online Q-learning to learn the optimal policy and maintain appropriate inventory levels within the supply chain in real time. For our COVID-19 mask scenario, we assume we have a pre-trained agent at t=0 that has learned a policy π, which maintains production p and inventory level i across all production plants and distribution centers for some expected demand d. If d increases to 10d at t=1, the agent would increase p and i per our Q-learning equation. Let’s say we already know we need 5p to maintain the correct inventory levels, but the agent increases p to 10p, causing an overstocked inventory at t=1 and receiving an actual reward of -1.
Now, when the agent sees an expected demand of 10d again in the future, it will be able to better adjust p to maximize its rewards, and with more data and time, it will learn the optimal policy and continue to change it whenever necessary to maximize its expected reward. Note that even with a pre-trained policy π, the agent can quickly change its policy to reflect changes in its environment. Furthermore, it can do this with every single data point in real time. This demonstrates that RL agents have the potential to resolve supply chain challenges in a sophisticated and expeditious manner while dynamically adapting to forecasted demand.
Reinforcement learning limitations
RL has certain limitations of its own. For instance, it does not scale efficiently to high-dimensional problems. Memory constraints may become an issue, and the state-action space may just be too large to explore in a reasonable amount of time. To address such limitations, newer techniques such as deep RL can be used.
Evolving optimization techniques
Optimization of supply chains has emerged as a critical challenge with profound effects on markets and daily life. While classical optimization techniques have provided a reliable, global solution for supply chain optimization, they have failed to keep pace with the volatile markets of today. The advent of AI and prescriptive analytics has shown promise in addressing supply chain issues, but has only provided local solutions, which are insufficient for complex global supply chains.
RL, at the intersection of optimization and AI, offers a compelling solution. The example presented above illustrates how RL can adjust to real-time changes and devise an optimal policy for solving a wide range of supply chain problems elegantly. When facing limitations such as scaling to high-dimensional problems, techniques like deep RL can also be applied. Therefore, we anticipate RL will offer effective solutions to increasingly intricate supply chain problems, providing a new perspective and approach to maximizing the value from businesses' supply chains.
If your organization is thinking through how to apply technologies like reinforcement learning, mathematical optimization or AI and needs a partner, reach out to our experts at marketing@credera.com.

Blog
Jan 4, 2023
Benefits of AI: Increase Efficiency, Enhance Safety, and Improve Reliability
Artificial intelligence (AI) has been hailed as the ultimate catalyst in propelling the incredible growth of companies...



Blog
Dec 14, 2022
How to Implement Marketing Automation: Five Tiers and Where You Fit
Marketing automation helps create seamless and highly personalized cross-channel experiences by delivering relevant and...


Blog
Mar 4, 2020
An Introduction to Intelligent Content: How to Make Your Content Work for You
Content is everywhere. It comes in many forms and is delivered across an ever-increasing number of channels. Content is not...

Contact Us
Let's talk!
We're ready to help turn your biggest challenges into your biggest advantages.
Searching for a new career?
View job openings